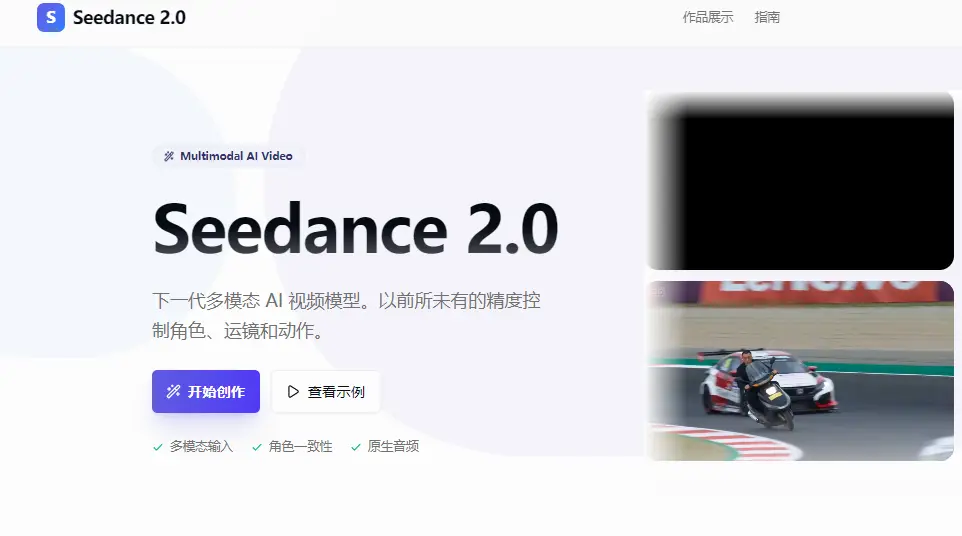
根据官方Seedance2.0说明的特点和具体亮点表现是参考能力上:
Seedance 2.0 现在支持图像、视频、音频、文本四种模态输入,表达方式更丰富,生成也更可控。
- 1.参考图像可精准还原画面构图、角色细节
- 2.参考视频支持镜头语言、复杂的动作节奏、创意特效的复刻
- 3. 视频支持平滑延长与衔接,可按用户提示生成连续镜头,不止生成,还能“接着拍”
- 4. 编辑能力同步增强,支持对已有视频进行角色更替、删减、增加
即梦地址:https://jimeng.jianying.com/,预计过几天会全量开放;截止目前,小云雀app已上线2.0,可去试用看看。
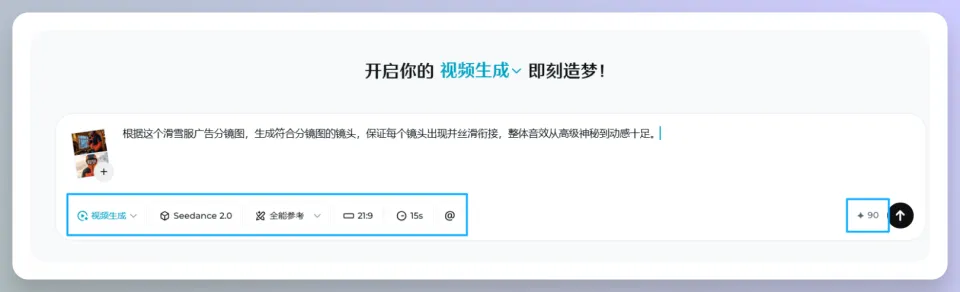
九宫格+提示词
提示词:根据图片九宫格,还原符合当下的剧情和人物神态和音效,人物语言使用四川话。
以上视频是由下面九宫格图片+上面这句提示词,在即梦用Seedance2.0生成。

整体环境和人物一致性完全满足,就是画面有部分丢失,可能是我选了10s的原因,导致无法全部演绎,因为我看@AI猫工头 罗马假日的案例,就很不错,而且提示词非常简单,就:四川话,罗马假日。
原创分镜图转视频
上面九宫格都是经典电影场景,可能会觉得是语料库训练过所以还原得比较好;那么我这个滑雪服的案例,纯原创发挥,未参考什么经典,同样生成得不错。
这图片是我之前在lovart生成的单独6张分镜图,现在是一起截图下来用。
分镜图生成的可看这篇:一张图怎么扩成完整电影镜头?这套提示词让AI全面得像剧组

根据这个滑雪服广告分镜图,生成符合分镜图的镜头,保证每个镜头出现并丝滑衔接,整体音效从高级神秘到动感十足。
这是一次性抽卡的视频,毕竟真的没积分去再次抽卡;其实你看图片第三格滑雪服的裤子颜色是橙色的,其它都是蓝色;但是视频生成从一而终都是保持蓝色滑雪裤的一致性,惊喜!
一键出TVC效果秒杀当时Sora 2,真的哪里还需要我学习,全靠模型自己升级,我直接用!
本次花费了500积分。
整体测试下来,真的惊喜多多,全能参考虽晚但到,主要还是生成质量的把控特别突出。不愧我周末一大早起床围观和实测。
不管是可灵3.0还是Seedance2.0,这种进步都肉眼可见的;可能今天我们还在聊怎么保证人物一致性,脸部不变形的技巧;明天模型自动给你解决这个问题,那我们是不是真的不用学习了。
其实不然,看似普通人做AI视频的门槛更低了,首先经济的成本可一点不会少,只是模型的进步会减少抽卡的可能性。
同时,更多传统视频专业人员导演、分镜师等也开始进入AI赛道,他们带着经验而来,普通人想脱颖而出的空间是更少。
所以如果想专注这个赛道,只依赖一键生成还是不可取的;就好像整体的SOP可以是10步,8步,或者3步,需要你知道本来是怎样的,才能有想象力去优化这个流程和精进。
无论这个赛道多么拥挤,稀缺的内容和好故事,永不过时。


.jpg)


:从入驻到变现,一站式实操指南.png)